打造IC人才
科技生态圈
打造IC人才
科技生态圈
发布时间:2023-03-21
来源:IC修真院
今天我们就从芯片设计的全流程重新总结一下如何压低芯片的功耗。
1. 为什么要压低芯片功耗
这事儿其实好理解,原因很多,比如电源网络不好设计,芯片容易失效等等。但是最重要的我认为就两点(敲黑板):
续航太短,散热太大。
对于移动设备,比如手机,电池供电的,功耗太大会缩短续航,你肯定不乐意充电一整天,电话三分钟。
那要是插电设备呢?你肯定不乐意用个核显还非要上个水冷。所以综上所述,功耗要尽量做小就是了。
2. 集成电路的功耗来源
既然要优化功耗,我们先看看功耗是怎么造成的。现代大规模集成电路里面广泛用的是CMOS, Complementary Mosfet, 互补的晶体管。原理上上下两个晶体管不同时导通,应该没有功耗,妥妥的永动机(狗头)。但实际上有非理想因素在,功耗就是这么产生的。
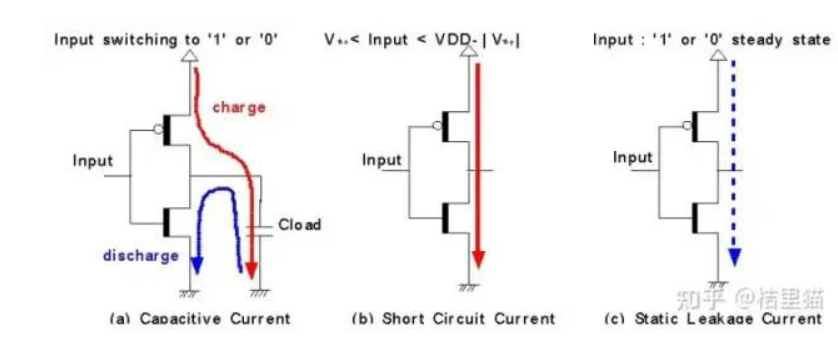
· 电容充放电电流。看图a,
实际上晶体管与地之间是有电容的。所以输入从0到1变化的时候会导致这个电容充放电。当input为0的时候能量从VDD冲到了电容, input
为1的时候能量直接流到地。
· 短路电流。由于晶体管非理想,存在某个电压,NMOS和PMOS都导通,导致直接有VDD到VSS的通路。产生电流。
· 漏电流。漏电流是input稳定的时候,其实vdd和vss之间也有细微的电流流过产生功耗。
电容充放电和短路电流是动态功耗,漏电流是静态功耗。动态功耗一般来讲远大于静态功耗。抓大放小,我们这个地方主要记住大头充放电功耗怎么算的。
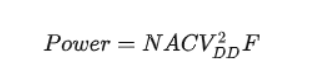
N是晶体管数量。
A是翻转因子。
C是寄生电容。
V是电源电压。
F是频率。
所以power和VDD二次方成正比,和频率一次方成正比。主要降低功耗也就是围绕这几个因子来转。

为了后面看着方便,这五个变量,代表了什么,再复习一遍233
3. 功耗优化全流程
此处我们给出一个功耗优化全流程中各个时间点需要注意的功耗优化方法。图似乎有点小。看详细说明。
需要注意两点:
1. 下图列的并不是全部的低功耗手段,只是一些我们容易干预的低功耗手段,比如在第四步流片造中代工厂显然可以优化工艺,降低漏电流,不过对芯片设计来讲这已经属于环境因素了。
2. 下图只列了芯片功耗的优化,在5步骤封装测试还有板级功耗优化,不在芯片设计讨论范围内。
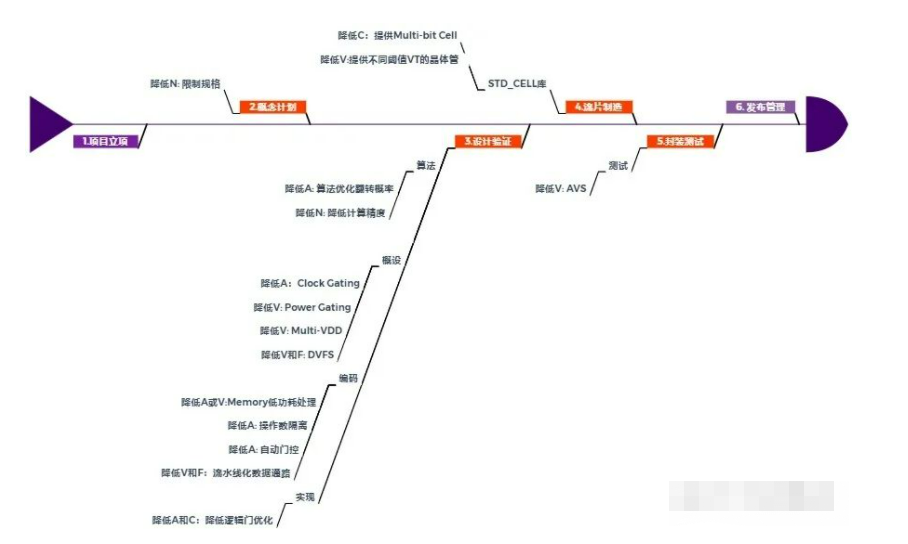
3.1 概念计划阶段
降低N:限制规格。概念计划阶段优化功耗的手段虽然不多,但是效果其实是最明显的。盛传一句话,上面一张嘴,下面跑断腿。概念计划就处于这么一个上面的位置。后面操作只能说是功耗优化概念阶段确定的规格可以直接框定功耗的大致范围。此处团队需要深入了解市场,确定什么功能要解决市场的痛点,必须做进去,什么东西是个伪需求,不要做进芯片徒增功耗。比如人脸识别的芯片你非要加入一个GPS导航,这功耗不就上去了。再比如给笔记本的芯片,你强行造出一个台式的功耗,肯定也是不行的。
识别什么特性是必须的,什么特性可以砍掉,是功耗重要,还是性能重要。在概念计划阶段就要搞明白。
比如下面这两个东西,功耗肯定是差异巨大的。

3.2 设计验证阶段
功耗优化的大部分手段出在设计验证阶段。我们一个一个来讲。
3.2.1 算法
算法阶段优化此处介绍三个常用的。
降低A和N:减少计算复杂度。算法最有效的做法是直接减少算法的复杂度。比如同样一个人脸识别的AI芯片,在识别精度相同的情况下,使用VGG明显比使用ResNet甚至MobileNet这些轻量化网络费功耗的多。所以算法部门一个永恒的目标是如何在不太损失精度的前提下降低计算复杂度。有时候同样一个任务精度一样计算复杂度可能会降低十倍不止。

降低A:算法优化翻转概率。这个事情比较玄学。比如训练一个神经网络尽量让网络推理的过程中翻转概率最低。再比如算法来个自适应,在信号比较好的时候采用一个比较弱的信道估计,在信号不好的时候启动比较强的信道估计等。
降低N:降低计算精度。对于芯片来讲,除了特殊需求,大多数计算都是定点的。那采用什么精度的定点就很容易影响功耗。比如计算神经网络的时候,由于网络自身就可以容错,算法可以不断压缩定点。比如用个8bit, 4bit看看结果如何。这部分大量运用于各类芯片。尤其神经网络,通信等等。如何降低精度有一系列的办法。采用指数压缩分组定点化等等。举个简单的例子,可以让神经网络不通层有不同的定点化来降低计算精度。
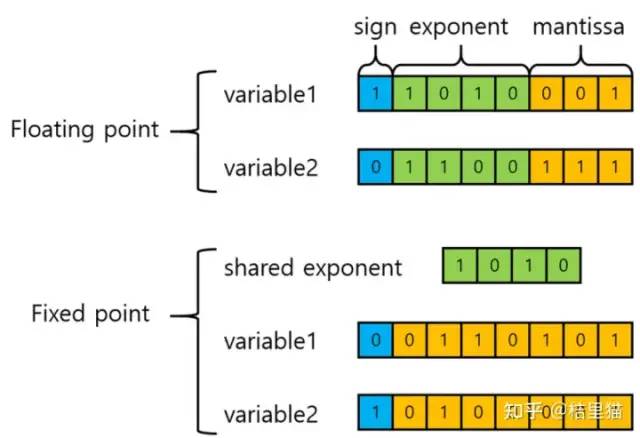
举个简单的例子,把两个浮点的指数为共享,这样相同精度下节省存储量,或者相同比特位宽提高精度。
3.2.2 概设
概设阶段主要是从模块级对芯片的功耗进行控制。
降低A:Clock Gating。一般模块级的clock gating信号要我们手动根据设计功能加入的。比如在CPU核没有任务的时候要把CPU的clock直接关掉,节省时钟网络的功耗。
降低V:Power Gating。对于能预测长时间不用的模块,要设计power gating 将不用的模块直接关掉。如下图所示,一个CPU系统,其实Memory可能不能掉电,Core和MAC什么的如果不用都可以power gating。
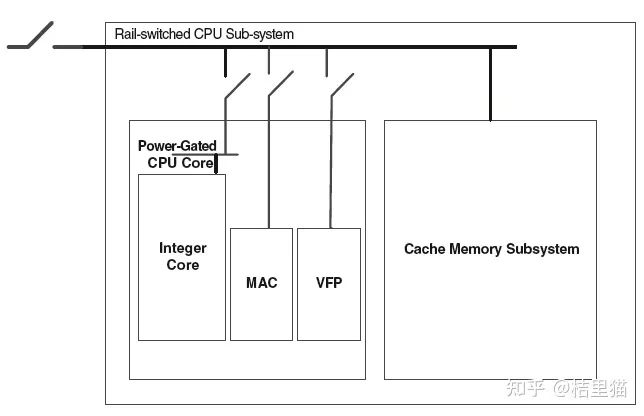 power gating有一定成本(功耗和面积上都有),所以一个模块要不要做power gating要逐个分析。
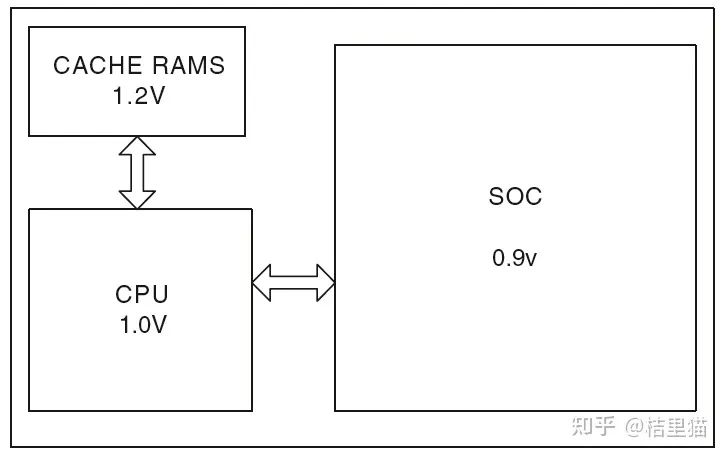
power gating有一定成本(功耗和面积上都有),所以一个模块要不要做power gating要逐个分析。降低V:Multi-VDD。现在的芯片都比较大,没必要所有模块都跑在一个电压下。比如下面这样,CACHE RAMS电压高一点,SOC部分电压可以低一点。
降低F: Multi-Clock Domain。
和上一条往往有联动关系,这个地方还附带有另一个效果,降低F。可以根据电压域讲芯片分为若干的时钟域,有些部分时钟慢一些来减小功耗。
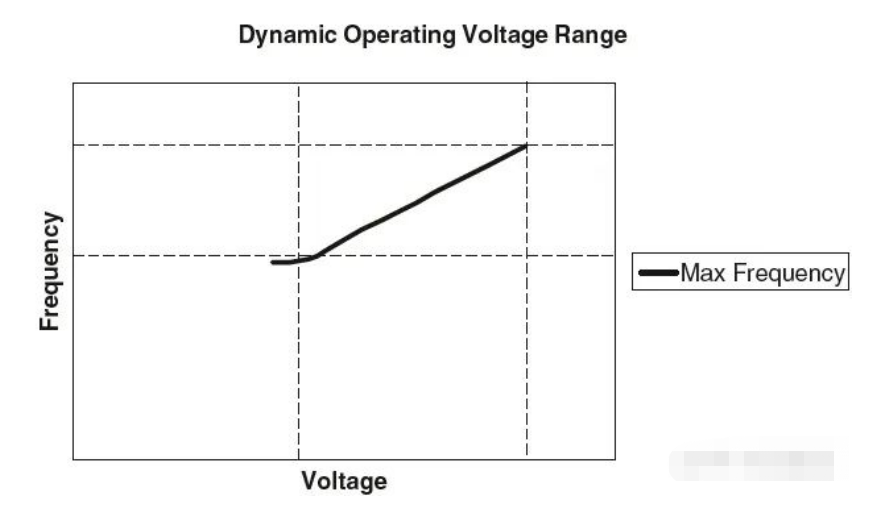
降低V和F:DVFS。Dynamic Voltage and Frequency Scaling。这个是现代芯片中非常常用的手段。根据业务负载自动的调整电压和频率。如下图所示,一般来讲,电压越高芯片能跑的频率也就越高。DVFS就是反其道行之。比如手机只有2G网,手机芯片就显然不用跑在最高频率。从而可以大量减少功耗。
 3.2.3 编码
3.2.3 编码
emmm 接下来就到了最喜闻乐见的编码阶段。。。

个人认为这个部分功耗的优化有用,但有的明显,有的不明显,和i++与++i有异曲同工之妙,比如常见的FSM状态机要用格雷编码事儿,就只能说节省了,但仿佛又没有节省。但由于编码自带炫技属性,所以写代码的时候还是要在意一下,此处讲讲我觉得最重要的三点。
降低A或者V:Memory Cell的低功耗使用。这个在编码阶段是绝对要注意到的。SRAM对于数据处理类的芯片来讲功耗开销非常大。这个我们重点讲讲:
· 存储量大的情况下尽量使用Memory。采用SRAM cell实现的读写比使用寄存器堆使用的读写省功耗。所以如果存储量够大,建议使用SRAM。
· 选用低功耗的SRAM Cell。SRAM cell一般都是由memory compiler生成的。比如购买ARM的compier. 一般来讲会提供各种类型的SRAM cell。尽量选择低功耗的SRAM cell。
· SRAM Cell要尽量使用低功耗mode。SRAM一般会留出power gating, deep sleeping, retention, clock gating等等端口,这些端口要根据实际情况用起来,SRAM不用的时候要把它低功耗起来。
· 避免无意义的读写。SRAM的读写都是有功耗的。比如访问嫌麻烦,降rd_en一直拉有效这种做法是要避免的。同时,即使没有wen, 数据端口信号变化也会产生功耗,能不变尽量不变。
降低A:操作数隔离。比如加法器乘法器这些部件,组合逻辑,只要操作数有变化就会产生功耗。所以采用操作数隔离,将不用的操作数直接置0可以省功耗。
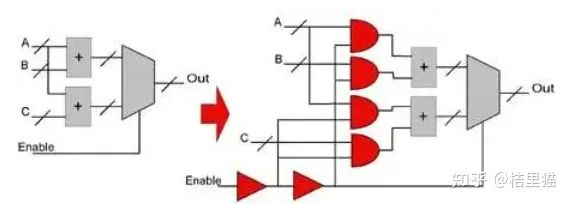
降低A:自动门控。这个非常好实现,节省功耗效果还算明显。综合工具可以直接帮忙加入。如下图所示,只要代码风格写的好,综合工具就能自动帮你门控。
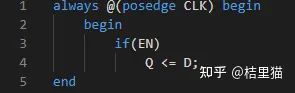
如果不开低功耗的综合,综合出的电路是这样的

如果开了低功耗的综合,综合出来就是这样的
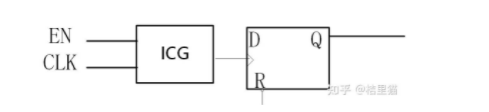
如果Q就1两个bit,那其实使用mux更省一些。如果Q比较宽,例如Q为32bit的话插入ICG就收益非常明显。
既节省了功耗,1个ICG肯定是小于32个mux。所以自动门控可以既节省功耗,又节省面积。
降低A:无复位寄存器。数据通路上往往还有办法。。。比如大量使用寄存器的地方,其实可以不用复位,采用无复位的寄存器,既可以节省面积,防止拥塞,又可以节省功耗。
3.2.4 实现
emmm 这个步骤主要是由DC搞逻辑门优化的骚操作。。。不需要我们干预什么,比如下面这样。
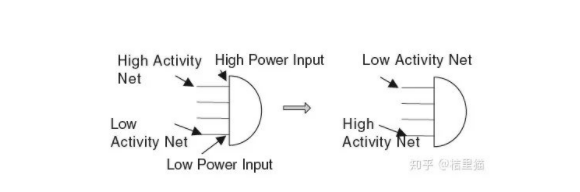
对于上面这种,对于一个门有可能各个Pin的功耗其实不一样的。把变化率低的信号mapping到低功耗的pin上就有好处。
3.2.5 较为激进的新技术
这部分可能目前的芯片不一定用的上。先提一嘴。等着技术发展。后面也可以专门写写这些新技术。
· Process In Memory,存内计算。能节省Memory到计算单元的搬运功耗。
· Nonvolatile Memory, 非易失存储。用非易失的存储,一方面,读功耗比SRAM小,二方面,不用就关电压。
· 亚阈值/近阈值技术。设计电路,降电压降到阈值附近甚至低于阈值。增大静态功耗的代价换取小的动态功耗。
3.3 流片制造阶段
这个阶段其实对于设计者来说大多数不可见的。我们讲讲两个可见的。主要是std_cell可以选择。理论上,随着工艺的演进,电压会降低,但是由于工艺越先进,一般芯片做出来频率越快,单位面积上的晶体管也更大,所以工艺演进对功耗的影响其实不好说。
3.3.1 Multi-bit Cell
比如寄存器,这个东西版图一般是由代工厂来给的。单个寄存器版图如下图。
如果这个东西不定制,DC会搞出两个一毛一样的cell,这时候提供这样一个2bit cell
或者这样提供一个4bit cell,功耗就能小。
能降功耗主要归功于clock pin电容降低了,时钟树uffer减小了。绕线也变短了。
3.3.2 提供不同阈值的晶体管
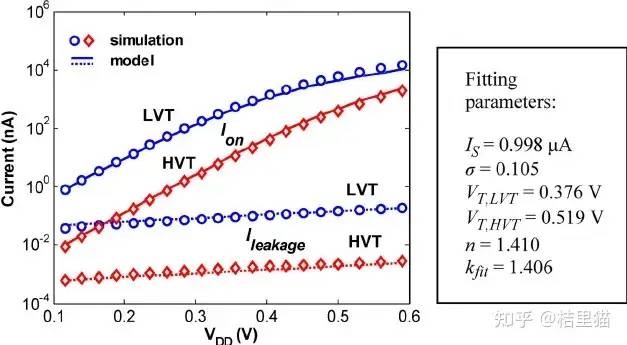
一般来讲,代工厂会提供好多种阈值电压的cell. HVT和LVT就是两种典型cell。HVT晶体管不容易switch, 功耗低LVT速度更快,但功耗更大。
3.4 封装测试阶段
封装测试阶段芯片其实已经都定型了,芯片本身的功耗优化还剩最后一个手段。。。AVS。AVS指的是Adaptive Voltage Scaling。基本原理是芯片做出来后筛选一波。有些芯片正好就造的比较好,那就降低点电压,有的芯片造的不行,只能提电压。由于工艺误差等等各方面因素,芯片就是有体质的不同...... 比如Intel CPU,有的能超频,有的超不动。这个阶段就在疯转测试阶段来做。筛片降功耗。

4. 总结
本文是这个系列的一篇彩蛋,讲讲从全流程如何优化芯片的功耗,只能讲个大概,实际情况还需要在项目中摸索。
相关推荐:

推荐阅读
2022-09-27
2023-04-10
2023-06-13
2022-10-09
2022-08-25