打造IC人才
科技生态圈
打造IC人才
科技生态圈
发布时间:2022-11-16
来源:IC修真院
不久前,英伟达和AMD将在中国暂停销售高端GPU的消息在芯片圈不胫而走。

美国证监会文件
根据美国证监会文件显示:这次被限制的不是常规意义上的GPU显卡,而是高端的商用芯片。据了解,该禁令影响了英伟达的A100和H100芯片以及包含这些技术的DGX系统和合作伙伴系统制造商使用的HGX平台;AMD也收到了美国当局的指示,要求停止向中国和俄罗斯销售其顶级GPU芯片MI250。
这些芯片是针对AI高速运算、HPC及数据中心场景而研发的。
然而,GPU“断供”事件在发酵中也出现了一丝转机。9月1日,英伟达在提交给美国证券交易委员会(SEC)的一份文件中宣称,已获得美国政府批准豁免,可以在明年3月前进行出口以支持A100的美国客户;允许在明年9月1日前通过其香港办事机构履行A100和H100订单和物流。
AMD也指出,新规定或不会对其业务产生实质性影响。
但尽管如此,新的GPU断供“风波”,再次揪紧了中国半导体行业的神经,也重新揭开了本土GPU产业的伤疤。

图源:nextplatform
慌张背后,再次吹响了加速国产替代的号角。
一记GPU组合拳
以上述英伟达A100和H100 GPU为例,A100芯片是英伟达2年前发布的一款3D堆叠芯片,集AI训练和推理于一身,号称当时全球最大的7nm芯片。
H100则是一款针对大模型专门优化的产品,今年3月在GTC大会上才发布,采用了最新的Hopper架构和台积电4nm工艺,拥有800亿个晶体管,最大功率800W,用于提升大型AI语言模型、深度推荐系统等。目前H100还未正式进入商用。
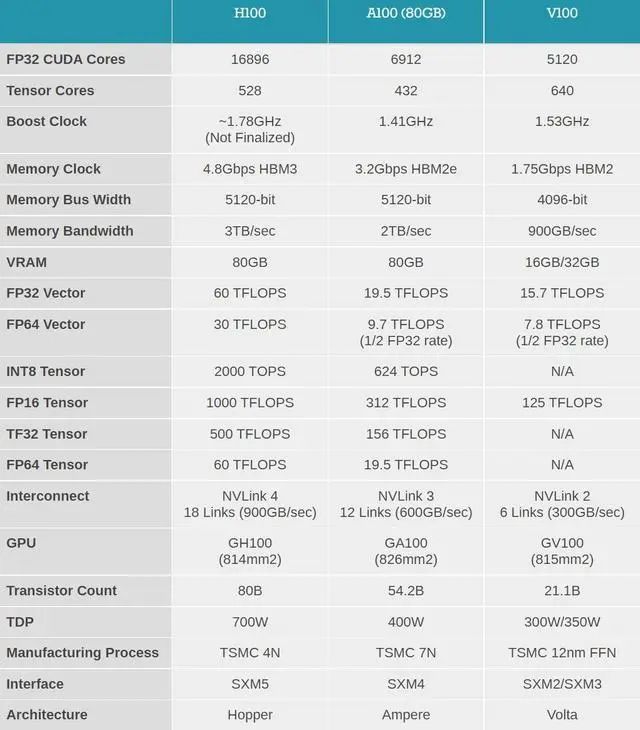
图片来源:anandtech
在中国市场,A100的用户包括阿里巴巴、腾讯、百度,这些公司主导着中国市场的云计算服务,提供按需计算和存储,也可以用于企业为人工智能应用编程。此外,英伟达的其他中国客户还包括联想和云计算及服务器提供商浪潮集团。
可见,国内GPU高端场景的GPU应用基本上都由英伟达的A100覆盖,今年3月份H100发布时,国内主流厂商也都已经预定。
针对这些GPU和相关DGX产品以及AMD产品的许可要求,多位业内人士表示,这是美国全面限制中国技术发展的组合拳。包括此前美国限制高端EDA的销售,以及联合半导体设备和晶圆代工厂,限制中国的先进制程芯片制造等,均旨在全面减慢中国的发展,尽量拖慢中国的发展速度。
对此,Truist Securities分析师表示:短期内,中国客户可能会转向不受许可证限制的老一代英伟达芯片;长期来看,这一行为将加速中国GPU芯片厂商的推进速度和投资力度,进而导致客户转向国内供应商。
事实上,我国高端GPU芯片进口从2019年以来就一直被限制,之前受限制的应用场景主要以超算中心为主,企业和消费者在产品端的感知并不强。而这次范围扩大之后,许多互联网大厂和服务器厂商都受到了影响,应用场景延伸到了云计算服务器、数据中心、AI训练等领域。
重压之下,国产GPU产业亟待突围,目前也已取得了一定成果。
近两年,国产初创GPU公司累计拿下超百亿融资——成立刚2年的壁仞科技融资总额超过50亿,摩尔线程一年融资30亿,沐曦集成电路第五轮融资10亿元,天数智芯也宣布拿下10亿元C轮融资...
巨额融资背后,是资本市场坚信国产GPU未来的信心和决心。
尤其近段时间来,国产GPU厂商除了陆续获得大笔融资以外,也在相继发布产品进展,切实在产品上取得了一定的突破。
国产GPU双线突围
按照用途,GPU可以分为通用GPU(GPGPU)和渲染GPU两种。
前者是用在AI深度学习和超算上的高性能加速卡;而图形渲染GPU就是比较传统的游戏、桌面,做各种图形化应用的GPU显卡。
在“断供”消息发酵之际,与英伟达、AMD股价大幅下跌相比,9月1日上午,国内上市的GPU及AI芯片上市公司股价普遍上涨,寒武纪股价大涨20%,景嘉微股价大涨10%,海光信息大涨16%...
与此同时,一些GPU芯片创新企业也不忘抓住机会释放讯号。在刚过去的2022世界人工智能大会(WAIC)上,天数智芯、壁仞科技、瀚博半导体、燧原科技、爱芯元智等国内一众GPU新贵芯片厂商悉数到场,宣布其最新成果和行业动态。
GPGPU市场火热
先来看GPGPU市场。
当前,云端需求和应用多样,既要做训练又要做推理,因此要求训练芯片要具备强大的单芯片计算能力,基本是GPGPU的天下。
GPGPU不具备图形处理能力,主要是用来计算原本由CPU处理的通用计算任务,实现一些AI训练和推理等方面的加速运算。
从市场现状来看,目前中国90%的GPGPU市场都被英伟达垄断。目前国产GPU厂商中,在这一方面发力的主要有天数智芯、瀚博半导体、璧仞科技等厂商发展较为迅速,正在快速布局积极追赶。
在今年WAIC上,天数智芯面市了其首款7nm制程的云端推理通用GPU产品“智铠100”,该芯片已于今年5月点亮,将于2022年第四季度正式发布,年底量产。智铠100正在进行第一批客户的验证和适配。
此外,基于天数智芯首款GPGPU天垓100芯片的加速卡“天垓100”亮相于去年WAIC上。截至目前,“天垓100”累计订单金额已经超过2.3亿,触达客户300多家,其中有意向签约的客户有200多家,覆盖行业超过20个,正在被推广到各式各样的互动场景中。天数智芯CTO吕坚平表示,天数智芯100%客户都是英伟达的客户,公司接下来目标是先拿下英伟达在国内10%的市场份额。
至此,天数智芯成为国内唯一同时拥有GPU架构下云端训练+推理完整解决方案的公司。
紧随其后,云端AI芯片公司瀚博半导体在发布会上预览了其首款7nm云端GPU芯片SG100,将图形渲染加入其产品布局。
据介绍,SG100具备业界领先的图形渲染性能,拥有超高吞吐、超高质量、低延时编码等能力,集渲染、AI、视频于一体,可为云游戏、云计算等元宇宙关键性应用场景提供深度优化。同时,SG100还提供SR-IOV虚拟化支持,端到端整体提升用户视觉体验,能够满足市场对智能视频视觉、图形图像处理的算力需求。目前该芯片还未正式发布。
去年,瀚博半导体发布了面向云端的通用AI推理芯片SV102芯片,其特点是推理性能高(单芯片INT8峰值计算能力200TOPS,还支持FP16/BF16数据类型),延迟低,视频解码性能。支持64路1080p(解码格式支持H.264、H.265、AVS2)。
SV102芯片中有专门的硬件视频解码单元,其视频处理和深度学习推理的性能指标比现有主流数据中心GPU高出数倍,可应用于云和边缘解决方案,节省设备投资,降低运营成本。
在一众国产GPU厂商中,壁仞科技算得上对标英伟达较为突出的一个。
8月10日,成立仅2年时间的壁仞科技就推出了首款通用GPU产品BR100系列,采用7nm制程,并创新性应用Chiplet与2.5D CoWoS封装技术,创出全球算力纪录。据透露,其16位浮点算力达到1000T以上、8位定点算力达到2000T以上,单芯片峰值算力达到PFLOPS级别,以“每秒1千万亿次的计算”算力纪录,超过了英伟达目前在售的旗舰计算产品A100 GPU的3倍,强势对标英伟达H100。
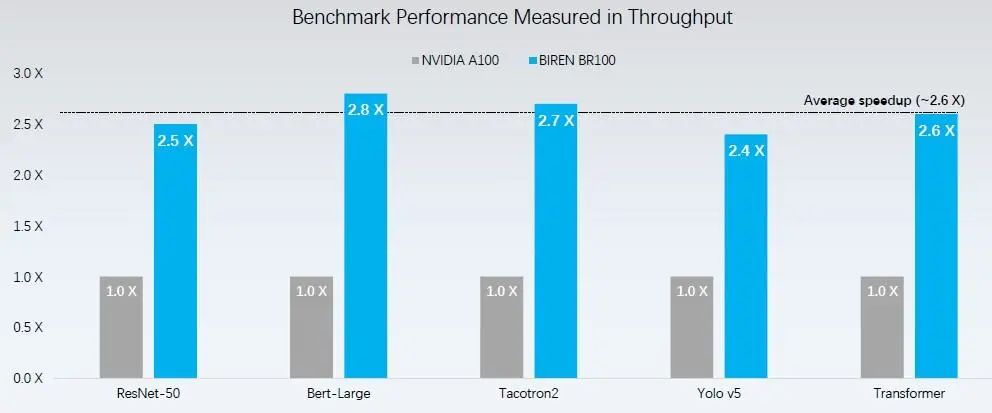
壁仞科技BR100与英伟达A100性能参数对比(图源:路透社)
目前BR100已流片回来,正在进行可靠性、稳定性等一系列测试,属于风险期小规模量产阶段,这个过程业内普遍需要9个月,但壁仞希望能在年底前完成,真正开始商用量产。
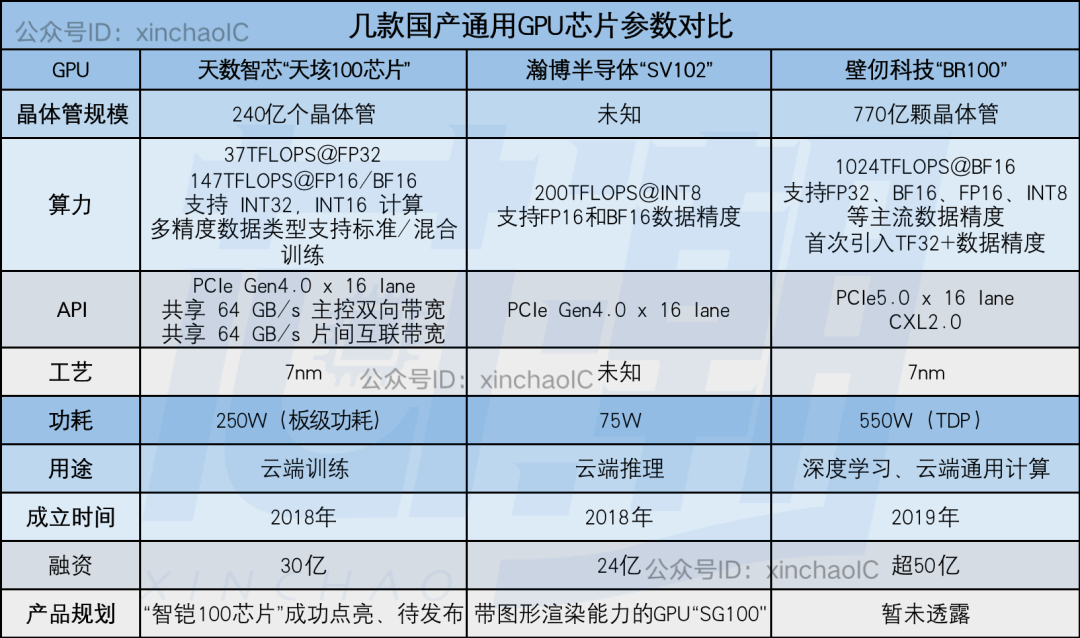
图源:芯潮IC
此外,昆仑芯科技、燧原科技、寒武纪、登临科技、沐曦集成电路、芯瞳半导体等国产GPU/AI芯片厂商也在紧锣密鼓的进行研发布局,加速国产GPGPU和AI芯片的发展进程。
渲染GPU跃跃欲试
当前,我们正在进入“一切需要可视化”的时代,图形可视化对于渲染GPU市场的需求增长迅速。
这几年,在诸多企业的努力下,除了最近上述企业在GPGPU方面的进展,国产GPU厂商在图形渲染GPU方面也在争分夺秒的交出有实力的产品。
在图形GPU领域,国内以芯动科技、格兰菲、景嘉微、摩尔线程等为代表的企业为主力。
芯动科技
最近几年,芯动科技将业务拓展至新赛道,着手GPU研发,目前是基于Imagination的GPU架构自主开发,同时采用全套自研高性能IP。和苹果公司一样,芯动在架构授权的基础上不断优化GPU内核,现已完整独立掌握了GPU内核演进架构图,实现了自己的GPU架构把控,并将以每年发布两款GPU的速度迭代演进。
去年,聚焦于数据中心、服务器领域的“风华1号”GPU正式发布,实现了国产5G数据中心服务器GPU应用场景从0到1的突破。
据了解,“风华1号”显卡实现了多项第一,如第一款渲染能力达到5T-10T FLOPS的国产GPU显卡,第一款图形API达到OpenGL4.0以上,并能实际演示4.0 benchmark的GPU,还是第一款支持多路渲染+编解码+AI服务,硬件虚拟化和Chiplet可延展的国产GPU等。

“风华1号”GPU性能参数(图源:芯动科技)
从芯片算力性能来看,“风华1号”双芯片B卡FP32浮点性能达到10T FLOPS,可以对标英伟达Tesla T4 GPU(FP32 / 8.1T FLOPS),且功耗更低。此外,风华GPU还搭载了Chiplet、GDDR6X以及虚拟化解决方案等众多优势技术,为产品提供赋能。
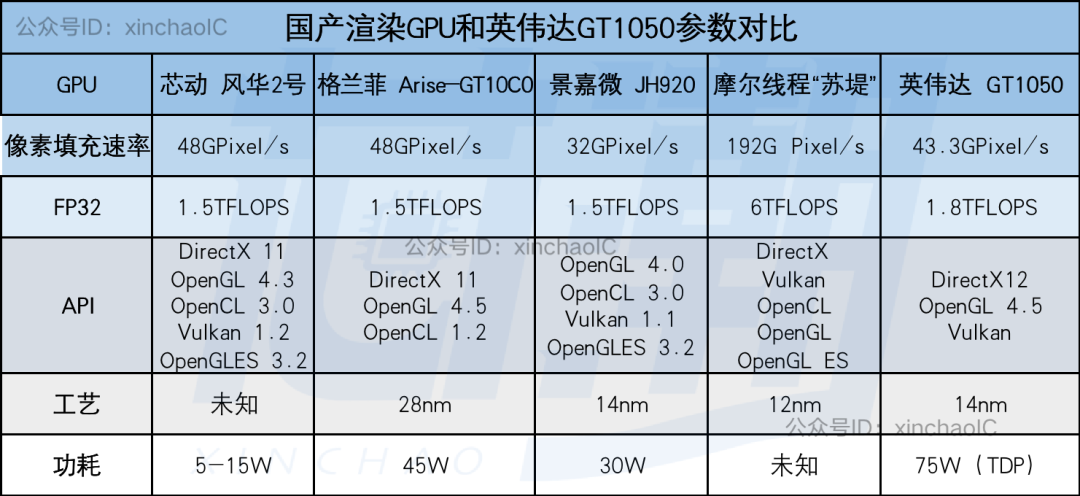
今年8月,芯动科技又推出了针对于桌面市场的“风华2号”GPU,“风华2号”渲染能力突出,GPU像素填充率48GPixel/s,FP32单精度浮点性能1.5TFLOPS,AI运算(INT8)性能12.5TOPS,实测功耗4至15W,支持OpenGL4.3、DX11、Vulkan等API。

“风华2号”GPU性能参数(图源:芯动科技)
作为参照,就像素填充速率和FP32来说,风华2号和英伟达GT1050大致处于同一档(GT1050像素填充速率为43.3 GPixel/s,FP32为1.862 TFLOPS,TDP为75W)。
芯动科技指出,“风华2号”是赋能桌面生态链的开始,将拉开风华系列GPU走向大众市场的序幕。目前“风华3号”已基本完成研发,将为国内用户提供超大算力光追等酷炫性能;同时,GPGPU和座舱产品也正与客户定义中,未来更多定制计算产品线将接踵而至。
格兰菲
格兰菲是兆芯GPU部门独立出去,同时吸引投资人入股成立的GPU公司,其技术源自2000年VIA收购的S3,走的是“技术引进-消化吸收-再创新”的路子。
格兰菲最新的显卡是Arise-GT10C0,是一款为桌面、商业显示以及通用计算等中高端应用场景,研发设计的第一款图形和图像独显芯片。其单精度浮点性能为1.5TFlops,GPU像素填充率48GPixel/s,主频500Mhz,工艺28nm,TDP为45W,支持DX11和OpenGL4.5、Vulkan等API。

Arise-GT10C0性能参数(图源:格兰菲)
从以上参数可以看出,Arise-GT10C0的规格看起来与风华2号相似,但功耗比风华2号GPU高上不少。
目前,对于格兰菲GPU的底层架构了解的不多,该公司没有透露GPU内核数量和时钟速度等基本规格。据报道,Arise-GT10C0显卡对标的应该是Intel Arc A380、AMD Radeon RX6400和英伟达GeForce GTX 1630 等独立显卡。然而,格兰菲在 FP32 模式下的 28nm GPU 只能与老式的 GTX750Ti 或AMD Vega 8集成显卡竞争。
兆芯
在核显级GPU领域,兆芯2019年发布了兆芯KX-6000,其核显与S3的C645规格和性能类似,甚至连驱动都能共用,3Dmark成绩为250分左右,当时集成的是C-960 GPU。
近日,有网站曝光了兆芯KX-6000G处理器的相关测试结果。3DMark显示,这款尚未发布的处理器集成了高性能的格兰菲Arise-GT10C0芯片,3Dmark成绩为1000分左右,相较于KX-6000提升了3倍,这个成绩和英伟达2012年发布的GT630差不多,性能作为核显是足够了,特别是当下党政办公Wintel电脑的独显也就这个水平。
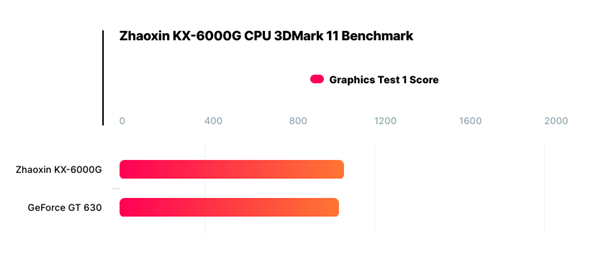
兆芯KX-6000G与英伟达GT630跑分比较
(图源:快科技)
景嘉微
景嘉微是中国第一家成立的GPU公司,产品主要分为图形图像处理系统、小型雷达系统、GPU芯片。
目前,景嘉微的最新GPU产品是JH920,是继JM5400、JM7200之后的第三代GPU,该芯片采用14nm工艺,支持OpenGL4.0、OpenCL 3.0、Vulkan 1.1等,但不支持DX。关键指标上,JH920像素填充率为32G Pixels/s,FP32浮点性能为1.5Tflops,功耗为30W。
从参数来看,JH920的性能与英伟达2016年发布的GTX1050相仿,GTX1050大概为英伟达10系显卡中的入门级产品,逊色于风华2号和Arise-GT10C0。
几个月前,景嘉微宣布其JM9系列第二款图形处理芯片已经完成了流片和封装,正在进行测试工作。根据测试效果来看,这款显卡的性能可以满足游戏、作图渲染等需求。
摩尔线程
另一边,成立于2020年的初创企业摩尔线程发展迅速,仅用18个月时间就发布了全新统一系统架构MUSA和全能GPU产品“苏堤”等系列新品,宣称完成了首颗国产全功能GPU的研制,纸面算力相当于2016年推出的英伟达GTX 1070。
据了解,摩尔线程的苏堤芯片是多功能GPU,不单只是有图形渲染引擎,还具备有多媒体引擎、AI计算加速,以及物理仿真与科学计算引擎,这可以满足更加广泛和不同平台的多元算力需求。
在实际的显卡产品方面,摩尔线程还同步推出了MTT S60和MTT S2000两款桌面级的独立显卡,其中MTT S60是面向PC和工作站的,MTT S2000则是专为数据中心打造的。
目前摩尔线程已与浪潮、联想、清华同方等服务器OEM达成合作。
图源:芯潮IC
另外,从事CPU研发的龙芯也开始切入这个赛道,正在不断增强国内GPU企业的整体研发实力。
综合来看,虽然上述厂商取得了一系列进展和突破,整体而言国产GPU的现状并不算乐观,虽然在特殊领域算是可以满足自给自足的需求,但是在中高端领域及个人消费领域还有着不小的差距。
要全面取代英伟达和AMD的GPU,不管是AI/FP还是渲染,目前还是不现实的。规格参数虽然能够一定程度上反映GPU的性能,但实际体验并不一定就与规格参数划等号。GPU核心设计能力不足和API支持不足,或是驱动方面的问题,都会导致GPU规格与体验倒挂的情况。
GPU是典型入门容易毕业难的行业。近期英特尔时隔20多年重回独立GPU市场,拉开架势发布的新品,表面看叠了不少buff,实际到了最考验功底的驱动程序方面,却被英伟达按在地上摩擦。所以对于新品牌的显卡来说,参数的意义往往有限,纸面上的数据最终需要市场来检验。
不过从中低端切入,再慢慢向高端渗透,最终进行取代,也是国产厂商们这么多年一直在走的路线,尽管现在还不行,但风波之下,确实也给国产GPU提供了一个机遇,带来了新的扩张机会。
不过,国产GPU仍前路漫漫,道路曲折,充满挑战。
国产GPU还要翻越几重山?
IP困境
IP的质量很大程度上决定了国产GPU性能的底色。
但由于IP研发难度大、开发周期长,目前中国GPU开发者大多使用Imagination提供的IP,GPU作为高性能的大芯片,想在短期内出成果,快速推出相关产品,必然需要依赖外部IP。
简单来说,就是购买一个商用GPU IP,然后自行修改迭代,如果IP供应商终止合作,那么就会面临研发、生产中断等问题。目前国内主流的GPU企业中,有不少都是采用的商用IP授权,只有景嘉微、天数智芯等少数企业有自研架构的GPU产品。
国内GPU底层技术空白点较多,IP大多受制于国外厂商,产品前端稳定性不理想,目前又很难在主线中高端电子产品上得到普及化应用,需多年沉淀形成自主IP积累才能具有一定替代性。
有声音表示,国内核心IP能力至少比英伟达、AMD等落后十年左右。而整体而言,GPU企业与国际大厂技术差距约3年,渲染GPU与国际大厂差距约10年左右。
软件门槛
有业内人士指出,计算芯片最大的门槛其实不是硬件,而是软件。如果一个芯片没有与之配套的软件生态,则很难真的形成大面积的应用,而这其实也是许多国内GPU公司的产品难以获得客户认可的原因所在。
英伟达当前竞争优势的形成,可以回溯到十几年前黄教主制定的战略,硬件领先竞争对手至少一个代际差距,软件做生态、建护城河。
据了解,2021年英伟达仅在显卡驱动测试工作上的投入就高达180万小时。而多年近乎垄断的行业地位,形成了很强的生态效应,让软件开发商更愿意为N卡进行针对性适配。
在当前GPU生态中,软件的权重已越来越高。Imagination中国区战略市场与生态副总裁时昕博士曾表示,GPU软件极为复杂,包括各种图形API和计算接口、基础库、与上层应用对接适配等等,开发工作量巨大。国内GPU生态的发展更需要“众人拾柴”,要加快打造国产GPU产业链,下游的整机厂商需要对国产GPU给予更多包容。
生态:强者恒强
对于国产GPU来说,产品如何实现规模化商用,搭建国产GPU生态同样是一个难题。
如果说砸钱可以买到IP,可以买到最先进的工艺,靠堆核心面积可以做出和英伟达类似性能的GPU,但是生态体系没有10年以上积累是做不起来。

图源:电脑技术
所谓生态,是指硬件架构和软件架构相互匹配。经过多年发展,英伟达已经构建了完整的技术生态,包括四层技术栈:硬件、系统软件、软件平台、应用框架。除了性能超强的芯片,英伟达为客户提供了快速实现AI模型训练和部署的软件系统,而且将主流AI算法模型通通开源,企业假如对某个AI算法缺乏积累,可以直接免费下载英伟达现成的先进模型,稍做调整就能落地应用。
开发者都是惯性的,尤其是在软件生态上,用户的使用体验已经形成,想要轻易移植难度很大。由于英伟达等国外龙头推出GPU时间更长,长期使用国外GPU的厂商出于惯性也不会突然更换国产GPU。
另一方面,ICViews在采访中指出:目前国产GPU在相同性能下,由于出货规模较小,导致价格更贵。在消费级市场,无法有效降低成本的国产芯片,往往价格偏高。不过,在更看重安全性和可靠性的企业级GPU市场,以及需要自主可控产品的一些行业,不存在C端那种明显的生态垄断,是国产GPU率先突围的赛道。
芯片的成功和成熟需要大量的验证和出货,而找到可持续的落地场景才是长期发展的关键驱动力。
市场认可度
另一方面还在于市场的接受度,在之前国外高端GPU芯片购买畅通的时候,国内芯片很难受到客户的认可,大家普遍的选择都是购买最先进、稳定的产品。
而国外先进GPU受到限制之后,也在提醒国内客户重新考虑外部的实际情况,从而也给国产GPU企业进入客户供应链提供了一次机会。
对此,百度资深系统工程师表示:“之前国产GPU有30%的性能提升可能都不会考虑,现在有30%的性能差距可能都不是问题了,毕竟刀架在脖子上,先用上再说。”
整体来说,GPU的研发牵一发而动全身,需要的不仅仅是企业的架构迭代与升级,还需要制造设备、材料、EDA软件等一系列配套产业的同步提升,才能缩短国产GPU与国际领先水平之间的差距。
目前,国产GPU在危机之下,正在酝酿新的生机。
结 语
GPU是一个高技术含量的赛道,是一项系统工程,包含硬件架构、算法、软件生态等多个组成,缺一不可。我国在这一领域已经落后许久,尽管近年来突然开始有不少初创公司踏足GPU领域,并受到资本青睐,但想要彻底打破GPU垄断也绝非易事。
目前,虽然很多国产GPU厂商的纸面数据,已经可以和英伟达2016年前后的10系产品掰掰手腕,但在调试以及软件适配方面的差距,不是一朝一夕就可以完成的。
GPU芯片技术具有很强的马太效应,在芯片行业,领先者与跟随者的差距缺的不是资本,而是技术洞察、战略规划、还有超过十年时间的落地执行。
这片巨大的市场,目前正吸引着越来越多资本的涌入,国内投资GPU的热潮既是商业化的需求,也是国家战略替代的需求,给国产GPU的发展添了一把火。
不过,也有观点强调:“我们也不能忽视这背后的投机属性。一方面,一些GPU新势力尚没有明确自己的细分市场,没有想清楚未来长远的发展方向,还只是停留在PPT阶段,所以尽管热度高涨,但真正能用产品说话的企业还较少,尤其是高性能商业化的渲染GPU产品凤毛麟角;另一方面,GPU技术门槛高,长期被国外行业霸主垄断,新势力想要生存必须掌握核心技术,有多年的技术积累和人才资金供给。”
总的来看,如今的GPU市场略显浮躁,很多初创公司通过竞相融资来“秀肌肉”,像极了通过比拼烧钱来争胜负的互联网公司。但烧钱模式是难以为继的,通过烧钱,迟早会烧出越来越大的窟窿。
每一个硬件公司、芯片公司,只有保持良性正循环,只有踏踏实实服务客户,服务市场,并且能够不断的回收研发成本,进一步实现创新,不断通过一个胜利来赢得下一个胜利,才是国产GPU的成功之路。
长远来看,GPU领域要面临一定程度洗牌,国产GPU将在竞争中将会逐渐由多家公司收敛成屈指可数的几家公司,那个时候才是真正的国产替代、缩小差距的开始。
道阻且长的国产GPU赛道,在市场、政策和资本的推动下,正在百花齐放,在危机中寻找生机,或将迎来发展的黄金时代。
相关推荐:

推荐阅读
2022-11-24
2023-06-08
2023-03-16
2022-08-02
2023-03-01