
AI编译器课程以通用NPU硬件架构与MLIR编译器工具链实践(开源工业级框架)为核心平台,沿着“理论认知→工具掌握→技能进阶→项目实战”的主线,通过手写MLIR优化Pass、模型转换全流程跟踪、INT8量化精度对比、YOLOv8Stream实践,以及Qwen大语言模型NPU部署等六个由浅入深的Lab实战,系统性地带你打通从AI编译器底层原理到在真实边缘硬件上完成工业级模型高效部署的全链路工程能力。
适合人群:
计算机科学与技术、人工智能、微电子、集成电路、电子信息、自动化、智能科学与技术、物联网工程、通信工程、应用电子等相关理工专业的本科及本科以上毕业生。
有 AI 算法开发、模型训练、Python/C++ 开发、嵌入式 Linux 相关经验,希望进一步掌握 AI 编译器、模型优化、边缘部署实战能力,满足企业高薪岗位需求的工程师。
有数字芯片、NPU/TPU、FPGA 开发基础,熟悉电路、系统架构等知识,规划向 AI 编译器、模型优化、边缘 AI 部署方向发展的工程师。
有一定算法、嵌入式、芯片开发相关基础,希望向 AI 编译器、边缘计算、模型部署等高价值方向进阶发展的工程师。
有 AI 开发、嵌入式开发、芯片应用相关经验,想要学习 AI 编译器全流程实战项目技能、提升就业与职场竞争力的工程师。
培养目标:
深入理解 AI 编译器全流程架构,熟练掌握模型解析、中间表示 IR、图优化、量化压缩、算子适配、硬件映射、推理部署等核心技术。
与项目团队协同工作,具备良好的逻辑思维、工程实现与问题排查能力,能够将业务需求转化为可落地的模型编译与部署方案。
熟练使用 AI 编译器工具链完成模型转换、校准、编译、调试与性能分析,确保模型在硬件平台上高效、稳定、低延迟运行。
熟悉模型量化、图优化、内存复用、算子融合等优化流程,提升模型在边缘硬件上的算力利用率、帧率与响应速度。
掌握编译调试、性能分析、精度修复、异常定位等工程能力,能够独立解决模型部署中的常见问题。
掌握 AI 编译器工具使用、命令脚本、环境配置与日志分析,对编译与部署体系具备完整理解与实践认知。
编写项目文档、实验报告、部署说明与性能分析记录,确保开发过程可追溯、可复现、可交付。
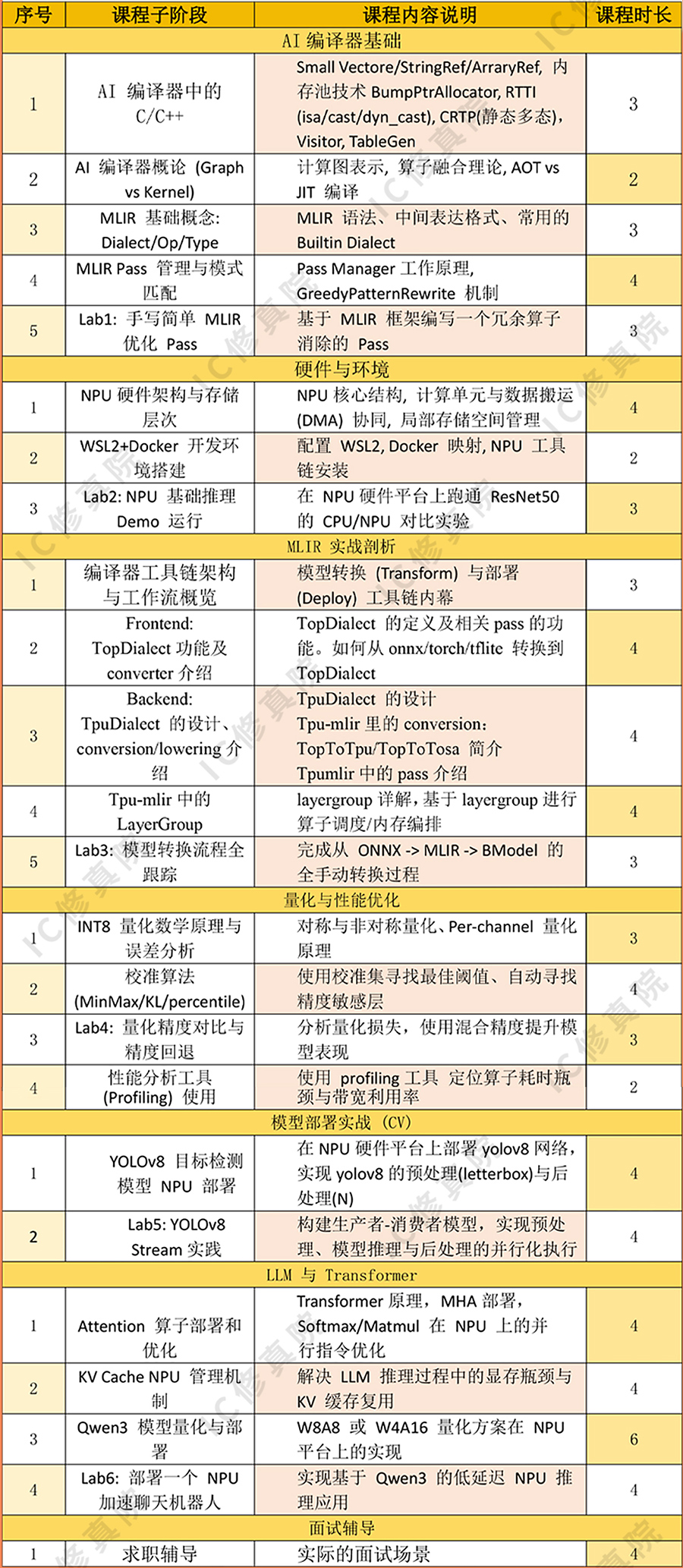
课程大纲:
AI 编译器框架图:
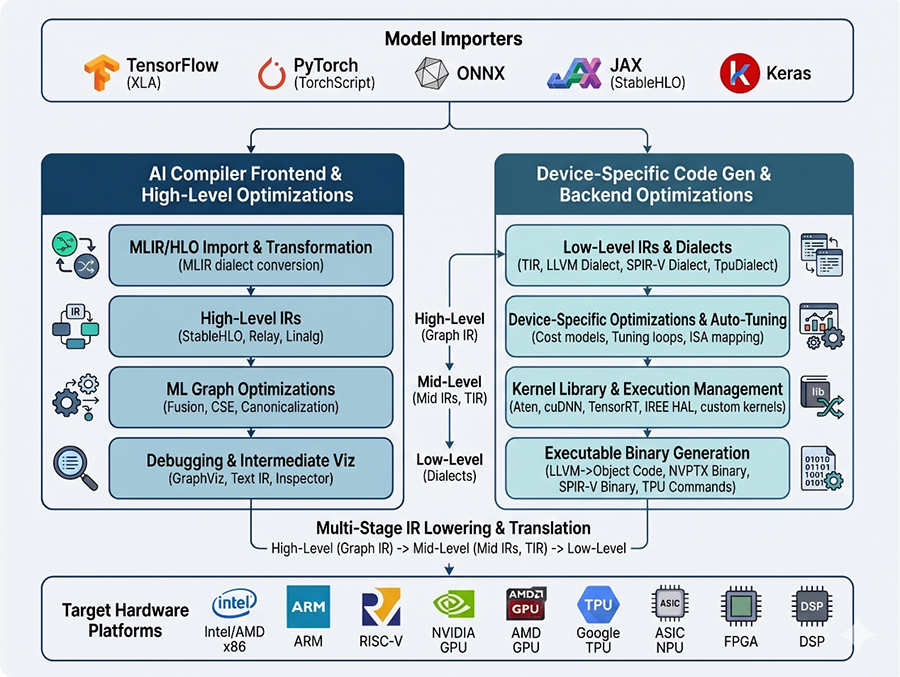
1. 模型输入层
功能说明:位于架构图最顶端,代表编译器的输入端。编译器支持解析并接收来自各类算法框架的模型,例如图中标注的 TensorFlow、PyTorch 以及通用的 ONNX 等格式
2. 编译器前端 (Compiler frontend)
功能说明:位于图的左侧区域。前端的核心职责是将不同框架传入的模型统一转换成通用中间表示(IR),并进行初步的优化处理
高级 IR (High-level IR / Graph IR):图中左侧框图展示了模型被转换为图级别的中间表示。这是一种硬件无关的表达方式,主要用于描述计算逻辑和计算图结构,极大地方便了后续的图优化工
计算图优化 (Computation graph Optimizations):即前端优化。这是在计算图上执行的与硬件无关的优化步骤,图中清晰列举了具体的优化方法,如 Algebraic simplification(代数化简)、Operator fusion(算子融合)、DCE(对应大纲中的死码消除/无效计算剔除)等。前端处理完毕后,会输出“优化后的计算图 (Optimized Computation graph)”供后端继续处理。
3. 编译器后端 (Compiler backend)
功能说明:位于图的右侧区域。后端的任务是把前端传来的优化后的计算图,最终转换为硬件可执行代码,这一阶段包含了大量硬件相关的优化操作。
硬件专属优化 (Hardware specific Optimizations):针对具体的芯片架构进行性能提升。包含图中列出的 Memory allocation(内存分配)、Memory latency hiding(延迟隐藏)、Loop oriented opt(循环优化)以及 Parallelization(并行调度与并行化)等。
自动调优 (Auto Scheduling / Auto-tuning):通过参数化和成本模型,自动寻找最优的执行策略和参数,以达到最佳性能。
调用底层加速库 (Using kernel libraries):在编译过程中,会直接调用芯片厂商高度优化的底层算子库,如图中注明的 Intel DNNL、NV cuDNN 等。
低级 IR 与代码生成 (Low-level IR & Code generation):为了生成具体的指令,后端会将通用表达转换为与硬件强相关的低级 IR,这种 IR 可以描述细粒度的执行逻辑。最终通过代码生成模块,输出针对具体硬件的可执行程序。
4. 目标平台 (Target platforms)
功能说明:位于图的最底部。经过前后端完整的转换与编译后,模型被部署到各类适配的底层硬件平台上,图中涵盖了常见的通用芯片如 CPU、GPU,以及定制化 AI 芯片如 ASIC (包括 TPU 等)。
讲师介绍:
辛老师:
背景:清华大学计算机系博士学位
经验:12年AI编译器与高性能计算工作经验
履历:曾就职于达摩院。主导开发了面向自研NPU的MLIR编译器工具链,实现了从TensorFlow/PyTorch模型到自研芯片的端到端部署,在算子融合、自动调优和内存优化方面取得显著成果。对TVM、MLIR、XLA等主流AI编译器框架有深入理解,精通LLVM/MLIR基础设施、计算图优化、多面体编译技术及异构并行编程模型,拥有多项AI编译器相关专利。
胡老师:
背景:复旦大学微电子学与固体电子学硕士学位
经验:10年数字前端设计与NPU架构工作经验
履历:曾就职于寒武纪,担任高级NPU架构工程师。深度参与多代智能处理器IP的架构定义与设计,负责NPU计算单元(脉动阵列、向量单元)与数据通路(DMA、片上缓存层次)的规格制定与性能建模。熟悉AI编译器后端与硬件的协同设计,在TPU Dialect定义、指令调度、LayerGroup切分与内存编排等方向有丰富的工程落地经验。精通Verilog/SystemVerilog、HLS高层次综合以及NPU性能仿真平台搭建。
罗老师:
背景:浙江大学电气工程学院硕士学位
经验:9年模型优化与边缘AI部署工作经验
履历:曾就职于旷世科技,担任模型部署与性能优化专家。负责将人脸识别、目标检测、语义分割等CV模型高效部署至高通、联发科、地平线等边缘平台。精通INT8/FP16量化校准算法、混合精度部署策略、计算图剪枝与蒸馏压缩技术。在大语言模型边缘化部署方面有领先实践经验,成功实现LLaMA/Qwen系列模型在端侧NPU上的量化推理与KV Cache优化,对跨平台推理框架(ONNX Runtime、MACE、TensorRT)有深入实战积累。
职业规划目标
通过学习 AI 编译器实战课程,直接对口的岗位有:
1、AI 编译器工程师
负责 AI 芯片编译器工具链开发、模型转换、图优化、量化工具、算子适配与硬件映射工作。需求企业:AI 芯片公司、算法框架公司、头部 AI 企业、云计算厂商。
2、边缘 AI 部署工程师
主要负责 AI 模型在边缘硬件上的编译优化、工程落地、性能调优与系统集成,将算法转化为可商用的端侧智能应用。需求企业:智能安防、车载 AI、工业视觉、机器人、新能源、物联网企业。
3、模型优化工程师
负责模型量化、剪枝、蒸馏、图优化与算子优化,结合 AI 编译器实现端 /边/云全场景高效部署,是 AI 产业刚需核心岗位。
4、AI 芯片应用工程师
面向芯片厂商与方案商,负责客户模型适配、编译调试、方案落地与技术支持,属于芯片产业核心技术岗位。
对于技术能力的加深,可以有以下发展方向:
技术专家:专注 AI 编译器、模型优化、异构计算、大模型编译等前沿方向,成为领域资深技术专家。
项目经理:发展项目管理能力,负责 AI 编译器、模型部署、边缘计算类项目的计划、进度、质量与团队管理。
架构工程师:深入理解 AI 编译器与芯片体系架构,发展为编译器架构师、部署架构师、端边云协同架构师。
管理职位:向团队负责人、研发主管、技术总监方向发展,负责团队规划、人才培养与业务落地。
创业机会:凭借 AI 编译器与边缘部署核心能力,开展行业解决方案、技术咨询、定制化部署服务等创业方向。







